The eBPF Virtual Machine
Let's discover the eBPF VM layer, how eBPF programs are built and loaded into kernel.
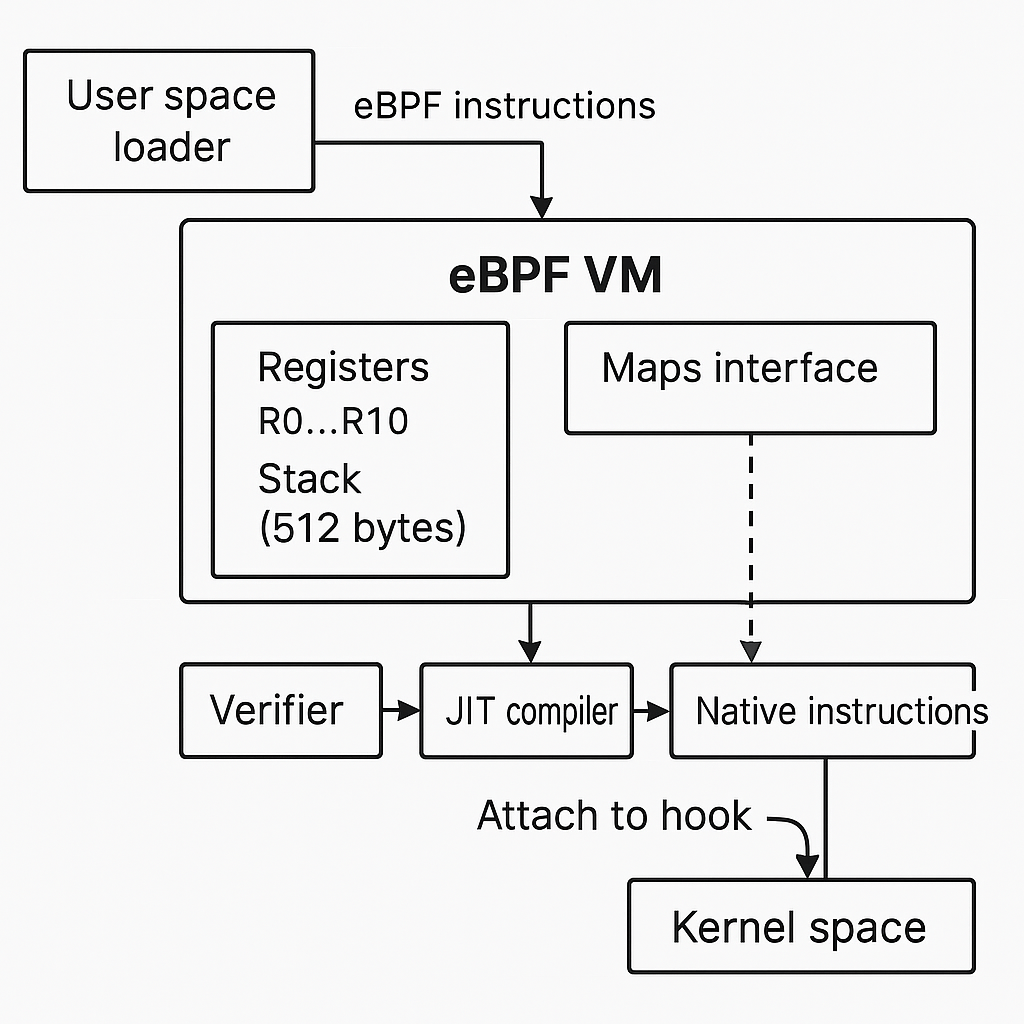
An eBPF program is a set of eBPF bytecode instructions, (eBPF code can be written directly in this bytecode, but higher-level programming languages are easier to deal with). We could say, eBPF is written in C and then compiled to eBPF byte code.
This bytecode runs in an eBPF virtual machine within the kernel.
The eBPF Virtual Machine
The eBPF VM, is a software sandbox inside the kernel that provides a secure and isolated environment to run the verified bytecode directly. Like any VMs that translate the program machine code into native machine code, the eBPF VM takes in a program in the form of eBPF bytecode instructions, and these have to be converted to native machine instructions that run on the CPU. And don’t be confused with the KVM (Kernel-based virtual machine), that turns kernel act like a hypervisor.
Historically the eBPF VM was only available from within the kernel and was used to filter network packets only (Berkley Packet Filter). The user space interference was only exposed via the bpf() system call and uapi/linux/bpf.h since kernel v3.18.
eBPF registers
eBPF bytecode consists of a set of instrctions, and those instructions act on eBPF registers (software virtual registers)
bpf() system call
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
SYSCALL_DEFINE3(bpf, int, cmd, union bpf_attr __user *, uattr, unsigned int, size)
{
return __sys_bpf(cmd, USER_BPFPTR(uattr), size);
}
static int __sys_bpf(enum bpf_cmd cmd, bpfptr_t uattr, unsigned int size)
{
/**/
err = security_bpf(cmd, &attr, size, uattr.is_kernel);
if (err < 0)
return err;
switch (cmd) {
case BPF_MAP_CREATE:
err = map_create(&attr, uattr);
break;
case BPF_PROG_LOAD:
err = bpf_prog_load(&attr, uattr, size);
break;
case BPF_PROG_ATTACH:
err = bpf_prog_attach(&attr);
break;
case BPF_PROG_DETACH:
err = bpf_prog_detach(&attr);
break;
default:
err = -EINVAL;
break;
}
return err;
}
Load a program
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
static int bpf_prog_load(union bpf_attr *attr, bpfptr_t uattr, u32 uattr_size)
{
/* ... */
err = security_bpf_prog_load(prog, attr, token, uattr.is_kernel);
if (err)
goto free_prog_sec;
/* run eBPF verifier */
err = bpf_check(&prog, attr, uattr, uattr_size);
if (err < 0)
goto free_used_maps;
prog = bpf_prog_select_runtime(prog, &err);
if (err < 0)
goto free_used_maps;
/* ... */
}
function bpf_prog_select_runtime() select exec runtime for the BPF program. It tries to JIT the program first, if not available, use interpreter. The JIT code is a part of architecture code since each arch require different way to translate eBPF bytecode to machine native code.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
struct bpf_prog *bpf_prog_select_runtime(struct bpf_prog *fp, int *err)
{
/* ... */
/* eBPF JITs can rewrite the program in case constant
* blinding is active. However, in case of error during
* blinding, bpf_int_jit_compile() must always return a
* valid program, which in this case would simply not
* be JITed, but falls back to the interpreter.
*/
if (!bpf_prog_is_offloaded(fp->aux)) {
*err = bpf_prog_alloc_jited_linfo(fp);
if (*err)
return fp;
fp = bpf_int_jit_compile(fp);
bpf_prog_jit_attempt_done(fp);
if (!fp->jited && jit_needed) {
*err = -ENOTSUPP;
return fp;
}
} else {
*err = bpf_prog_offload_compile(fp);
if (*err)
return fp;
}
/* ... */
}
The bpf_int_jit_compile() variants are defined at arch/<arch>/net/bpf_jit*.c.
Attach to an event
A demonstration
Benefits of this approach:
- Define its own eBPF instruction set -> not depends on the archicture -> CO_RE.
that able to access a subset of kernel functions and memory.